How our team at SAP Labs Singapore built an autonomous AI agent platform that now handles code, research, slides, patents, security audits, and half our merged PRs.
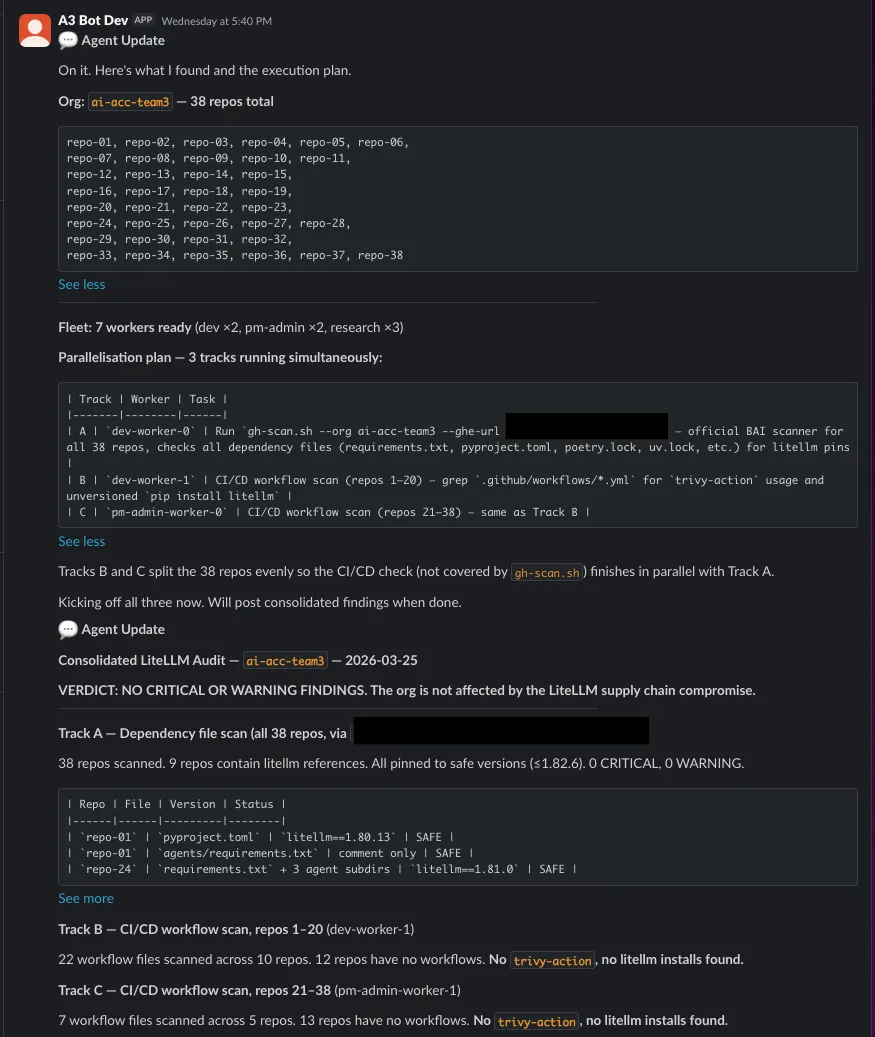
What an A3 fleet supervisor posted to Slack after coordinating a supply-chain vulnerability audit across 38 repos and multiple workers. The execution plan, task distribution, and consolidated findings were all determined by the agent, not hardcoded.
The audit that started with a Slack message
On March 24, a threat actor called TeamPCP published two poisoned versions of LiteLLM to PyPI: versions 1.82.7 and 1.82.8. LiteLLM is the Python package that sits between most AI applications and their model providers, downloaded roughly three million times a day. The malicious versions contained a multi-stage credential stealer: environment variables, AWS keys, Kubernetes secrets, SSH keys, everything exfiltrated to an attacker-controlled domain. The attack chain was cascading: TeamPCP had first compromised Trivy, the popular security scanner, then used stolen CI/CD tokens to pivot into LiteLLM’s PyPI publishing credentials.
Our team runs dozens of repos, many of them AI agent services that touch LiteLLM directly or transitively. When the disclosure hit, we needed to know, fast, whether any of our 38 repositories were exposed.
One person typed a message in Slack. Within ten minutes, every dependency file across every repo had been scanned, every CI/CD workflow checked for the compromised Trivy action, and a consolidated audit confirmed: zero exposure. All LiteLLM references pinned to safe versions. No trivy-action usage anywhere. The team had a confident answer before most organizations had finished reading the advisory.
That audit was done with A3, the autonomous AI agent platform we built on Kubernetes.
In the weeks since we started, the team has run more than 1,000 tasks and counting through A3: pull requests, code reviews, patent drafts, research, presentations, and more. Roughly half of the team’s merged PRs now come through the platform. One colleague built a patent drafting skill, iterated on it over a few sessions, and produced a complete internal draft in a day, a process that normally takes a week before anything reaches legal. Another delegates research daily via @A3 Bot in Slack with zero technical setup.
We built the platform in one month. None of these workflows were pre-programmed. This post explains how we got here and how it works.
Why we built it
Everyone on our team already uses AI coding agents. Some of us are power users running multi-session workflows; others are mostly using AI as a conversational interface. The adoption gap between those two groups is real and growing.
But even for the power users, the gains stay siloed. One engineer builds up a perfect set of project context files, custom skills, and workflows, and nobody else benefits. Their agent doesn’t know what your agent discovered yesterday. There’s no shared memory, no coordination, no way for one person’s breakthrough to lift the rest of the team.
The coding agent ecosystem in 2026 is capable at the individual level. Agent teams can coordinate subagents within a session. Background agents run tasks in cloud sandboxes. But all of these are scoped to one person, one session, one machine.
We wanted something different: shared infrastructure. Persistent workspaces with accumulated context, a durable task queue anyone can push to, coordinated fleets that can parallelize work across specialized roles. When one agent discovers something, it can broadcast to every other agent. And because the interface is just @A3 Bot in Slack, you don’t need to be a power user. The PM doing research and the engineer running fleet audits use the same entry point.
We wanted to find out what happens when you treat AI agents like shared infrastructure instead of personal tools.
The road here
A3 didn’t start as a multi-agent platform. It started as a single coding agent running in a container.
We wanted to run coding agents in the background without tying up a laptop. One container, one agent, one task at a time. It worked, but it was manual: SSH in, manage the session, copy results out. Only the most technical people on the team could use it.
The first evolution was a server. Instead of SSH, a thin API that accepts tasks and routes them to the container, wired to Slack so anyone could type @A3 Bot and get a response.
But one agent hit a ceiling fast. If it was busy with a 30-minute code review, a five-second question sat waiting behind it. We added Redis to track state and queueing for multiple workers, but the architecture was getting messy: Redis handling queuing, pub/sub, state tracking, and ephemeral storage all at once.
That’s when the problem clicked into focus. We were solving the same thing the infrastructure industry solved decades ago: how do you go from a single process on a single node to a fleet of coordinated workers across many nodes? Durable work queues. Capability-based scheduling. Health checks and automatic recovery.
We replaced Redis with a dedicated message broker handling both the durable task queue (at least-once distribution) and the event stream (fan-out to any number of consumers). A relational database became the source of truth for persistent state. And once we had multiple workers pulling from a queue, the next questions were obvious: can they talk to each other? Can one delegate to another? Can a supervisor plan and distribute work?
We added ten coordination primitives, send_task, wait_for_task, broadcast, ask_question, and others, and the system started composing behaviors we didn’t program.
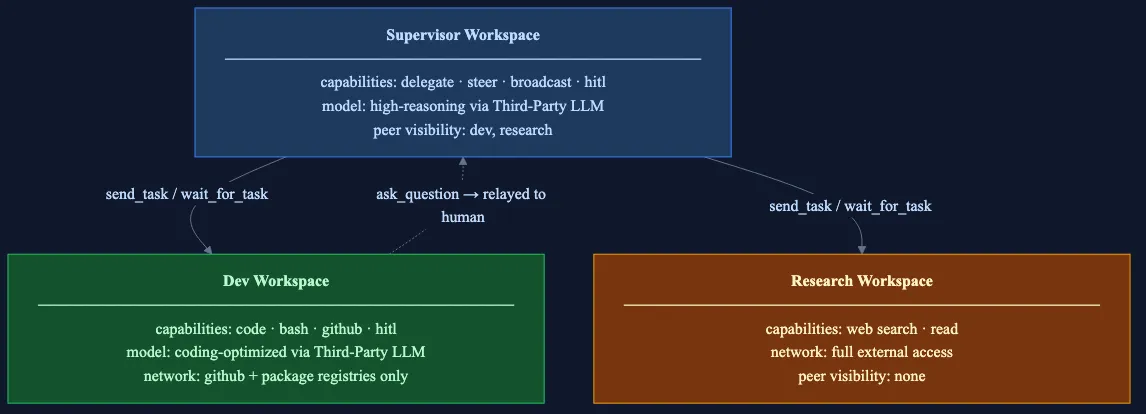
Fleet topology showing three workspaces: supervisor, dev and research. Each workspace can have multiple workers. Peer visibility arrows show delegation paths; ask_question bubbles up. A supervisor is just a workspace with delegation capability and visibility to others, no additional workflow code required.
The design philosophy: emergent principles
Most multi-agent systems we’ve seen fall into one of two failure modes.
The first is over-specialization. You build a dedicated coding agent, a dedicated review agent, a dedicated research agent, each with a narrow, human-engineered workflow. It works beautifully for the demo. Then a user asks for something slightly different and the system can’t adapt, because you engineered the flexibility out of it. You end up with brittle pipelines that defeat the whole point of AI.
On the other end of the spectrum is context collapse. You dump everything, every tool, every skill, every piece of context, into one model and expect it to handle everything. It works to a point, then the model is overwhelmed and can’t specialize. There’s no division of labor.
A3 aims for the best of both worlds. We provide full, generic capabilities. We don’t artificially constrain agents into rigid workflows for the sake of safety or efficiency.
Let them read, write, execute code, search the web, interact with APIs, the full set of things a human engineer could do. Then divide work into specialized workspaces so agents can focus by role, each with appropriate boundaries: a research workspace gets full internet access but can’t execute arbitrary code; a dev workspace can write and push code but has restricted network access; a supervisor can delegate and steer but can’t directly modify files in other workspaces.
The result: we don’t need a specialized coding agent, a specialized code review agent, a specialized patent drafting agent, or a specialized fleet executor. They all emerge from the same primitives. The composition of first-principles primitives gives emergent capability and adaptability, the way humans can improvise across domains rather than blindly executing a predefined script. We build the infrastructure to make it possible, make it scale, and make it safe even as agents run autonomously for increasingly extended periods of time.
Optimization comes after, not before. Once we see which tasks agents handle repeatedly, we build specialized skills and tools that agents can use at their disposal: accelerators, not guardrails. The starting point is full capability.
The architecture, through tasks
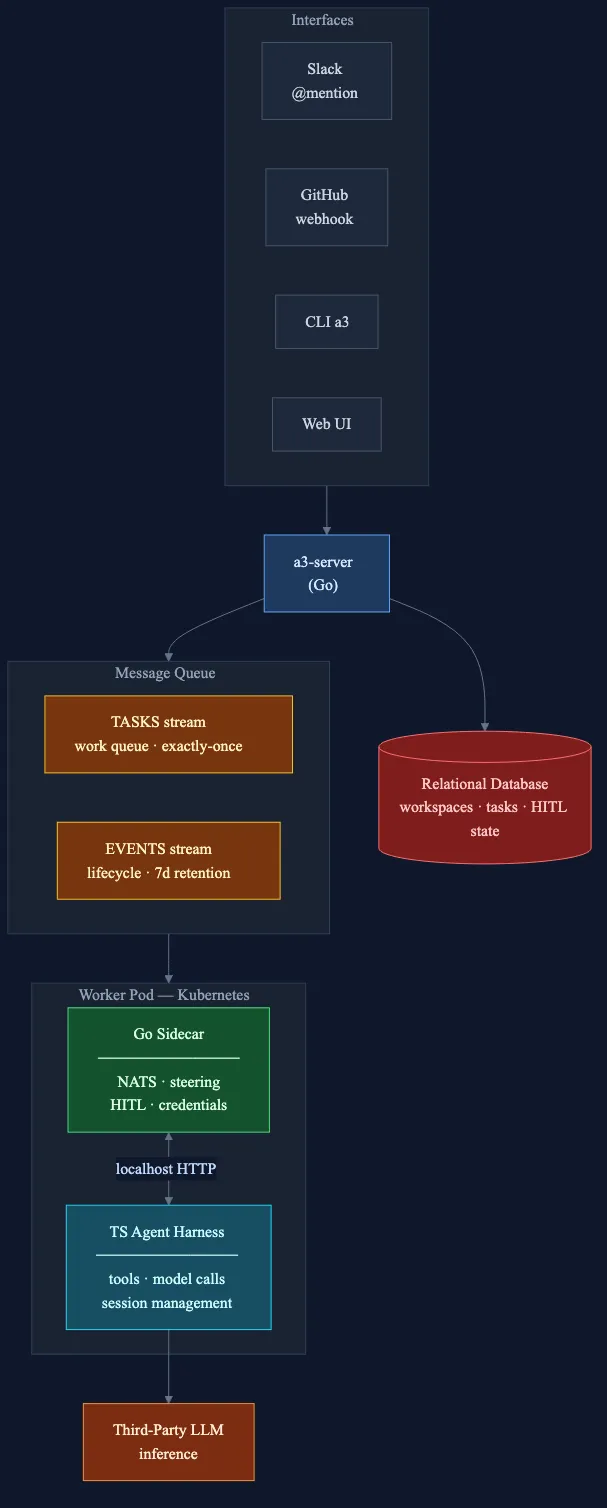
System architecture. Events from Slack, GitHub, and other sources flow into a3-server, which publishes to a message broker. The TASKS stream feeds worker pods (Go sidecar + TypeScript harness); the EVENTS stream drives auto-replies back to the source. A relational database stores state; third-party LLMs handle inference.
The best way to explain the architecture is to walk through what happens when someone actually uses it. Three scenarios, increasing in complexity.
A simple task
A developer types in Slack:
@A3 Bot add error handling to the upload endpoint in analytics agent.In the next few seconds:
- Slack sends a webhook to
a3-server, our Go control plane. The server verifies the signature, deduplicates the event, and publishes to the EVENTS stream via the message broker. - The event consumer routes it to the target workspace’s TASKS stream, a durable, at-least-once queue.
- A free worker pod pulls the task. Each pod runs two processes side by side, the platform/AI boundary. A Go sidecar owns all infrastructure: messaging, task queue, steering, HITL, credentials.
- A TypeScript harness runs the AI model via third-party LLMs.1 The sidecar and harness communicate over localhost HTTP through eight JSON endpoints.
- The harness executes the task, reading files, writing code, and running tests through MCP tools the sidecar registered at startup.
- Results stream back through the message broker to the server, which posts the output to the original Slack thread.
We meet our colleagues where they work: in Slack, GitHub, and through the CLI. A3 is natural to use and feels like talking to a colleague who learns over time.
The sidecar is the platform layer, written in Go and reused across all agent types. The harness is the AI layer, currently TypeScript wrapping the model SDK, but the protocol is language-agnostic. You could write a harness in Python for a different model, or in Rust for a specialized agent, without touching the sidecar. Infrastructure and AI are independently deployable and independently evolvable.
The whole flow is event-driven. Every significant action - task queued, task started, task completed - becomes a typed event in the EVENTS stream. The CLI, any future UI, and the event router all consume the same stream.
The developer doesn’t have to mention it, but the agent already knows the codebase. A3 workspaces are persistent: worker pods mount a volume that preserves the agent’s working memory across tasks. Our conventions, our error handling patterns, our preferred libraries, the system has built up context over weeks of use. It doesn’t ask “what repo is that?” or “which framework?” It knows, the same way a teammate who’s been on the project for months knows.
A stateless agent forgets. A colleague doesn’t.
Live steering and continuity
The developer watches the agent work in the Slack thread and notices it’s implementing retry logic with a fixed delay. While the task is still running, they reply:
@A3 Bot use exponential backoff instead of fixed delay.The server detects that this thread has an active running task. Instead of creating a new task, it publishes a steering message, injected into the agent’s context via hooks at the next tool-call boundary through the sidecar’s /steer endpoint. The agent adjusts course without restarting. No lost work, no new session. Like tapping a colleague on the shoulder.
Later, after the task completes, the developer sends another message:
@A3 Bot now also add integration tests for the retry logic.The server sees the thread mapping and that the previous task is complete. It creates a new task pinned to the same worker, with a continue_from reference to the previous task. The harness resumes the prior session with a session fork. The agent has full conversation history: what files it read, what code it wrote, what tests it ran.
Three forms of continuity: file system (same PVC, the code changes are still on disk), conversation (same session, the model remembers the prior task), and tool state (same git checkout, same working directory).
Cross-workspace delegation
The dev worker is implementing a new API integration and needs to look up how a particular authentication protocol works in the platform documentation. But the dev workspace has a restricted network profile: it can reach our internal GitHub and package registries, but nothing else. Network isolation is enforced at two layers: Kubernetes NetworkPolicy (L4) and Istio Sidecar/ServiceEntry (L7). The pod literally cannot make requests to blocked domains.
The agent knows this. Instead of failing, it calls send_task, dispatching a research request to the research workspace, which has full external network access. The research worker searches the docs, summarizes the findings, and returns the result. The dev worker integrates the answer and continues.
Delegation is governed by a capability intersection model. Every workspace carries a capability list (code, bash, github, delegation, slack, hitl, and so on). Every task can carry its own. The effective set is their intersection, whichever is more restrictive wins. If a workspace doesn’t have the delegation capability, the send_task tool isn’t just blocked, it’s never registered in the MCP tool list. The agent doesn’t know it exists.
Peer visibility adds another layer. A supervisor workspace with peerVisibility: ["dev", "research"] can only see and delegate to those two workspaces. The API rejects attempts to push tasks elsewhere. A worker can’t escalate its own privileges.
Different workspaces can also run different model tiers: a heavier reasoning model for the supervisor, a coding-optimized model for dev workers, a lighter model for research. Right-sizing the model to the role, just like right-sizing compute for a workload.
Human-in-the-loop
An agent working on a deployment task hits ambiguity:
“This will modify the production database schema. Should I proceed?”
The agent calls ask_question, an MCP tool that pauses execution and posts the question back to the originating Slack thread. The sidecar sends a stop signal, the harness cooperatively pauses at the next tool boundary, and the task status becomes paused. The worker pod is now idle, session saved.
The developer sees the question in Slack, and replies:
Yes, but only for the staging environment.
The server creates a resume task, pinned to the same worker, with the human’s answer as the prompt, and a session fork from the paused task. The agent continues exactly from where it stopped, with full prior context plus the human’s decision.
This pattern, deterministic pause, async human response, session-preserving resume, was one of the hardest things to implement correctly. The stop signal uses a belt-and-suspenders approach (dual message paths) because a missed stop means a runaway agent. And session forking prevents message interleaving: each resume is an independent branch.
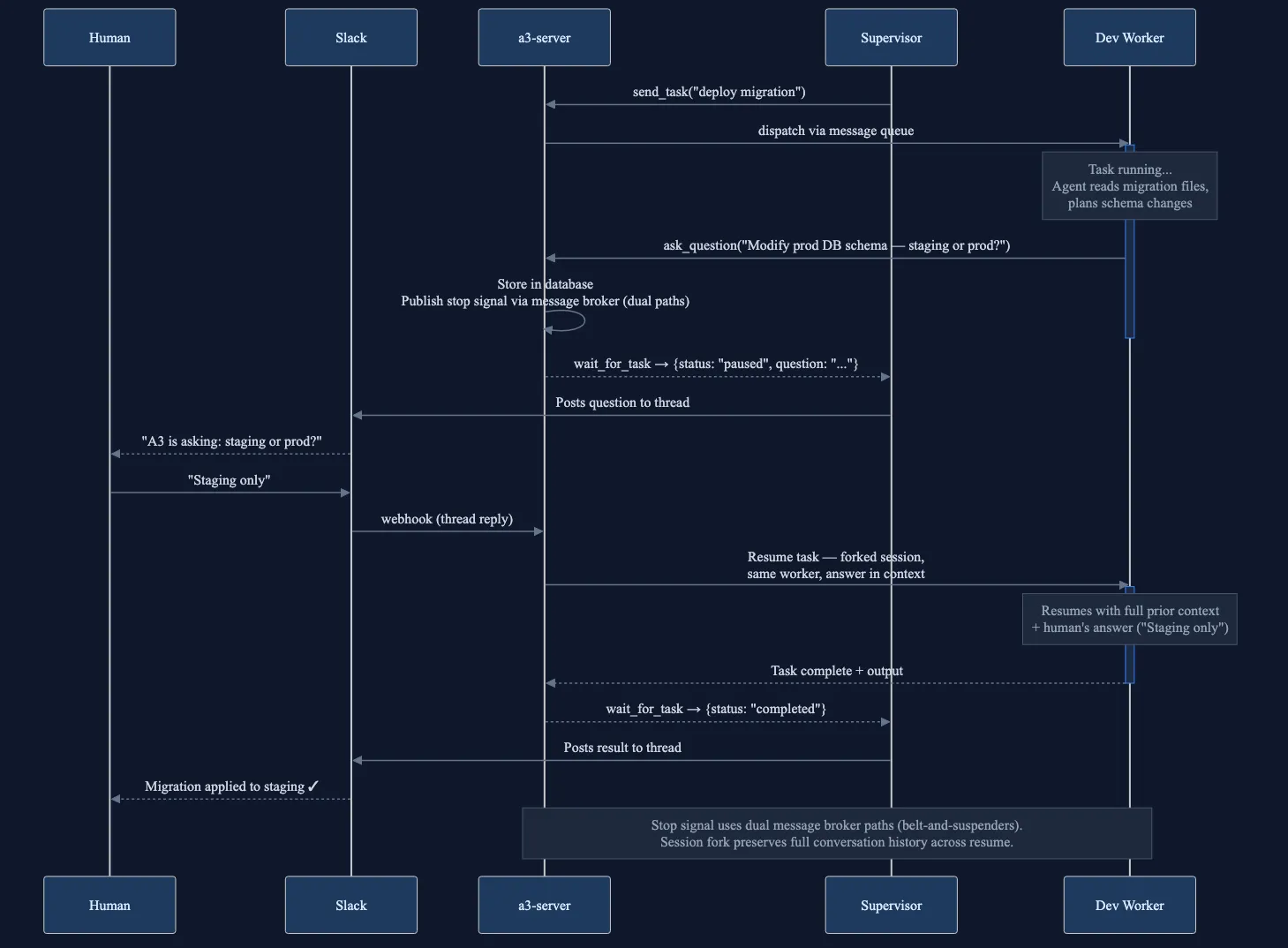
HITL sequence. Supervisor dispatches via send_task and blocks on wait_for_task. Worker calls ask_question; wait_for_task returns paused with the question. Human answers in Slack. answer_question creates a resume task pinned to the same worker. Supervisor re-waits on the new task ID. Worker resumes with full context plus the answer.
Safety: infrastructure over instructions
Because A3 runs autonomous agents with full capabilities within their workspace, safety can’t just be a prompt instruction they might ignore. It has to be infrastructure they can’t bypass.
A3 has four independent enforcement layers:
- Network. Kubernetes
NetworkPolicyand Istio sidecars control what each pod can reach. A research agent can search the web but can’t push code. A dev agent can push code but can’t hit arbitrary URLs. Enforced by the service mesh, zero agent involvement. - Process. The Go sidecar checks capabilities on every tool call. If the workspace lacks delegation, the
/a3/send_taskendpoint returns HTTP 403. Defense in depth: even if a tool name leaks through the harness filter, the sidecar blocks it. - Application. The harness only registers MCP tools that match the workspace’s capabilities. Unlisted tools are invisible, not just blocked. The agent doesn’t know they exist.
- Context. Peer visibility is enforced server-side. Workspace-scoped system prompts and memory. The agent can’t discover peers outside its visibility list.
Each layer holds independently. Compromise one and the others still stand. Compare this to prompt-based safety: “Do not access unauthorized systems.” That’s a suggestion to a language model. A NetworkPolicy is a kernel-level packet filter. The gap between those two things is the gap between hope and infrastructure.
But infrastructure handles authorization, not quality. The model can still go off-task, hallucinate tool calls, or produce code that passes linting but is functionally wrong. We mitigate this with workspace-scoped prompts that anchor the agent’s role, persistent memory that accumulates project conventions, and the HITL pattern for high-stakes decisions. We’re also building toward verification loops, automated checks that validate agent output before it reaches a PR. This is an active area, not a solved one.

Four independent layers: Network (Istio/NetworkPolicy, L4/L7, zero agent involvement) → Process (sidecar capability guard, HTTP 403) → Application (MCP tool filtering, unlisted tools are invisible) → Context (peer visibility, workspace-scoped prompts). Each holds independently.
The LiteLLM audit, in detail
Back to March 24. One person pasted the IT team’s security alert into Slack. A supervisor agent received it and didn’t start scanning immediately. First, it did what any good engineer would do: read up.
The supervisor pulled context from the disclosure, the PyPI advisories, and other sources online, then built a structured picture of the attack: affected versions, the Trivy attack chain, which dependency file types to scan, and the specific trivy-action GitHub Action to look for in CI/CD workflows. Then it planned the execution.
Phase 0: Discovery
The supervisor ran gh repo list on our org. Thirty-eight repos. Seven workers available: two dev, two pm-admin, three research.
Phase 1: Parallel three-track scan
The supervisor designed a parallelization plan and dispatched three tracks simultaneously via send_task:
- Track A: a dev worker ran an official security scanner against all 38 repos, scanning every dependency file (
requirements.txt,pyproject.toml,poetry.lock,uv.lock) for LiteLLM version references. - Track B: a second dev worker scanned CI/CD workflows for repos 1-20, grepping
.github/workflows/*.ymlfortrivy-actionusage and unversionedpip install litellm. - Track C: a pm-admin worker ran the same CI/CD scan for repos 21-38.
The supervisor split the CI/CD work evenly across Tracks B and C so that the workflow scan, not covered by the official gh-scan.sh tool, would finish in parallel with the dependency scan.
Phase 2: Synthesis
The supervisor called wait_for_task on all three tracks, then merged the results into a single consolidated report.
The verdict: no critical or warning findings. Nine of 38 repos contained LiteLLM references, all pinned to safe versions at or below 1.82.6. Zero repos used trivy-action. Twenty-nine workflow files were scanned across 15 repos with workflows; the remaining 25 repos had no CI/CD workflows to check. The org was clean.
A confident answer, with evidence, delivered in minutes. Before most organizations had finished triaging who should even look at the advisory.
The problem was well-scoped, so the plan was clean: two attack vectors, two parallel tracks, one synthesis. A3 has done more structurally complex operations, five or more phases, adaptive inter-phase dependencies, but complexity isn’t a virtue.
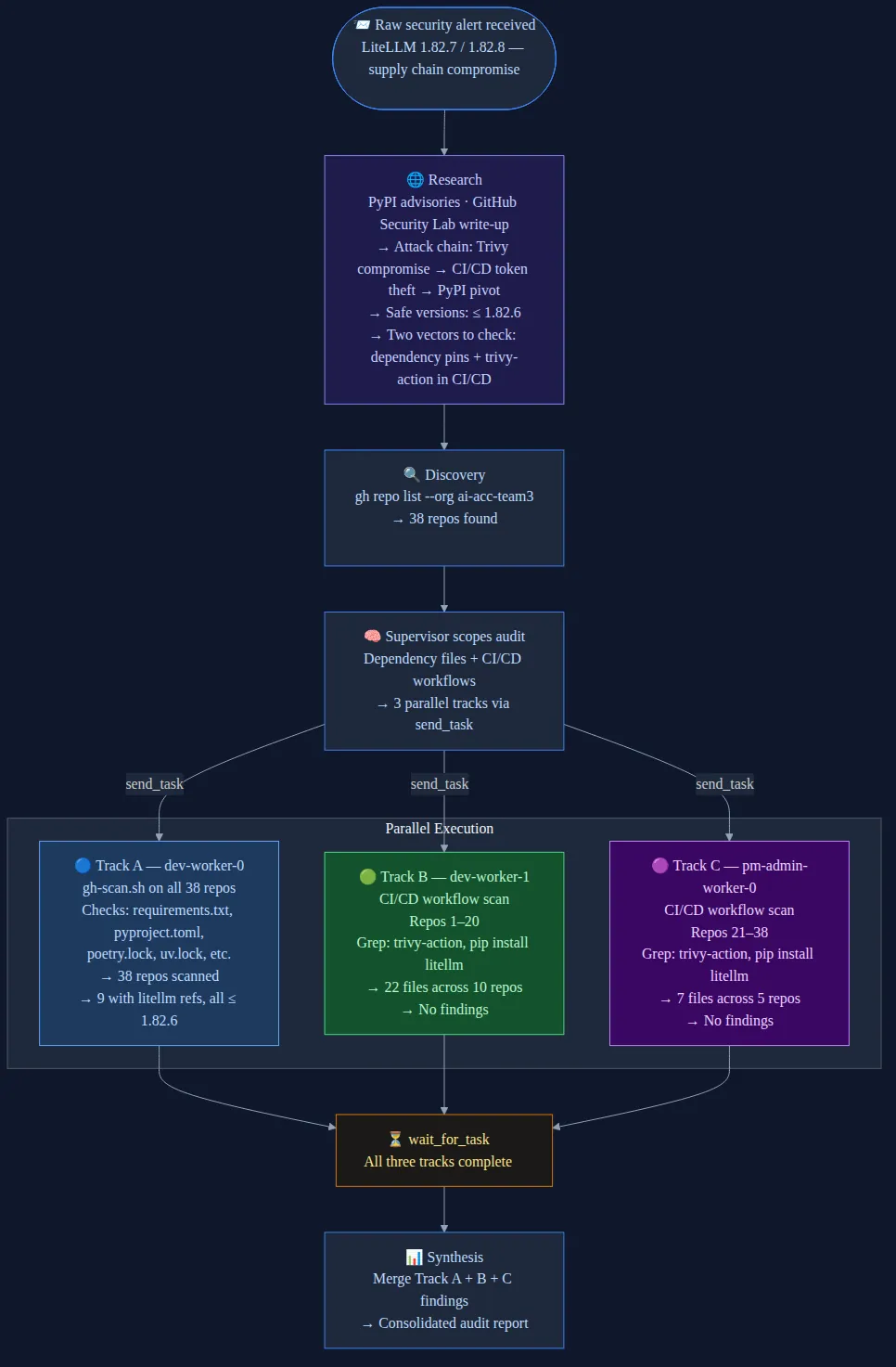
The supervisor researched the incident, decomposed the audit into three parallel tracks across four workers, and synthesized a consolidated verdict, all through Slack.
Four agents. Three workspaces. Two attack vectors. Thirty-eight repos. A real incident, a real answer, in minutes. Nobody wrote a “supply-chain audit workflow.” The supervisor invented one.
How we built A3 (with AI agents)
We wrote almost none of A3’s platform code by hand. The entire system, Go server, sidecar, TypeScript harness, Helm charts, message broker setup, Kubernetes manifests, was built using coding agents, both locally and through A3 itself as it became capable enough to contribute to its own development.
The workflow follows what the industry now calls the Research → Plan → Implement → Validate pattern. Never let the agent write code until it has researched the codebase and you’ve reviewed a written plan, and never consider a phase done until tests confirm it works. Every major feature starts as a vision document iterated with the agent until goals and trade-offs are clear, then evolves into a concrete architecture document. Only then does implementation begin.
For multi-session work, we use two continuity mechanisms. Architecture documents carry an embedded tracker: session notes the agent writes at the end of each session, so the next session can read state and pick up where it left off. For deeper context transfers, we use handoff prompts, condensed summaries that give a fresh session full continuity without a bloated context window.
We maintain a four-layer test suite: unit, integration against a real message broker and database instances, end-to-end on a live Kyma cluster, and live tests exercising actual model execution including steering and HITL round-trips. Every feature change maps to at least one layer. And once A3 reached basic functionality, we started using it to build itself, platform tasks pushed through the same Slack interface and task queue that users interact with.
What broke
We kept notes on every bug that took more than an hour to diagnose. All four of the worst ones were distributed systems problems, not AI problems.
- Task queue prefetch hoarding. The shared-queue fetch goroutine in the sidecar would
Fetch(1)and immediatelyAck()even while the worker was busy executing another task, buffering the message in a local channel. The task appeared stuck as queued in the database for twenty minutes while it sat in a busy worker’s memory, invisible to idle workers that could have picked it up. The fix was switching to synchronous fetch in the main dispatch loop with a one-second fetch timeout, so workers only pull when they’re actually ready to execute. Queue fairness was restored, and the observability gap (DB says queued but the task is actually acked and buffered) was eliminated. - HITL notification gap. The event consumer wasn’t subscribed to
task.startedandtask.pausedevents. When a delegated task paused for HITL, the supervisor’swait_for_tasknever got notified. Two-line fix, but the symptom was just silence. - Delegation TTL. Timeout-based TTL for delegation tracking broke for any task that paused for HITL or ran longer than expected. We fixed it by switching to a 24-hour fixed TTL.
- Dual-auth misclassification. The
/steerendpoint wasn’t in the internal auth paths. Sidecars couldn’t steer peers; they’d get 401s. Two-line fix that took disproportionate debugging time because the error surfaced as “steering not working” with no obvious auth failure.
Every one of these is a bug you’d find in any distributed system: message routing, TTL semantics, auth middleware, consumer prefetch semantics. If you treat agents like infrastructure, you debug them like infrastructure.
Where this fits
Stripe’s Minions are one-shot, unattended agents: one task, one PR, optimized for high-volume well-defined work across a massive codebase. Cursor’s long-running agents push how long a single agent can work autonomously, with multi-day runs producing enormous PRs. Spotify’s Honk system focuses on fleet-wide code migrations with strong verification loops to ensure predictable results at scale.
A3 occupies a different point in the design space: coordinated multi-agent work across heterogeneous tasks, with agents that persist and learn. The same platform handles a ten-second “summarize this link” and multi-hour audits across multiple workers, gracefully scaling from single-shot questions to coordinated parallel execution without the user changing anything about how they interact with it.
But unlike one-shot systems, A3 agents accumulate context over weeks of use. They learn your codebase conventions, your team’s preferences, your documentation structure. Each task makes the next one better. A supervisor dynamically plans and distributes work across specialized workspaces, agents share knowledge through broadcast and persistent memory, and the PM doing research uses the same @A3 Bot as the engineer running fleet operations.
The LiteLLM audit demonstrated something we haven’t seen described elsewhere: an agent composing a multi-phase execution plan at runtime from generic primitives, with adaptive dependencies based on intermediate results. Whether that’s the right point in the design space is something only continued use will tell.
What’s next
The orchestration primitives are deployed and validated. The LiteLLM audit was the first time all ten composed into emergent behavior on a real task. But the ceiling is higher.
- Shared memory. Right now, every delegated task has to include all relevant context in the prompt. The next step is a formal shared memory system: passive consolidation from transcripts, active read/write memory tools, and shared fixtures that load once into a workspace for all workers, reducing prompt size dramatically and ensuring identical standards.
- Workspace state portability. Thread pinning currently ensures follow-up tasks land on the same worker that has the file state. We’re designing a tiered system, reconstructed context from transcripts for simple follow-ups, delta capture for iterative tasks, thread pinning as a fallback, so any idle worker can pick up where another left off, like an OS context-switching a thread to a different core.
- Task pools. Currently, the supervisor must manually call
send_taskfor each work item and track availability. A task pool primitive, where the supervisor creates a pool ofNtasks, workers pull when ready, and results are aggregated automatically, would eliminate the manual distribution logic and enable much larger fan-outs. - Result streaming.
wait_for_taskcurrently blocks until all tasks complete, then returns everything at once. For long-running jobs with human oversight, streaming results as they complete would be a significant improvement. - Dynamic scaling. Worker count per workspace is currently fixed. Scaling up when queue depth exceeds a threshold and scaling down when idle, matching resources to workload, is the natural next step for a Kubernetes-native platform.
The architecture was designed with all of this in mind. The patterns just hadn’t been exercised yet. Now they have.
Update, June 2026: Two months after this post, Anthropic shipped Claude Tag — one shared agent per Slack channel, persistent memory, async delegation. The same multiplayer-agents-as-infrastructure bet, now from a frontier lab, and the safety story they led with is scoped permissions, memory isolation, and audit logs: infrastructure, not prompts.
We haven’t stood still since April either. Now live:
- Model and harness-agnostic — any model, any harness, swappable per workspace
- Durable execution — stuck tasks detected and retried from the last checkpoint
- Transcript-based context portability — tasks migrate across pods
- Multi-tenancy with RBAC and policy evaluation — your triggered tasks can only do what you’re allowed to
- Per-workspace managed skills and instructions
- Deeper internal SAP integration, plus a local-worker track that delegates to a scoped autonomous agent on your own laptop
In flight: user and team-scoped memory, self-improvement through “dreaming,” and more.
A3 was built by our team at SAP Labs Singapore Business AI. The platform runs on SAP BTP Kyma (managed Kubernetes) and uses third-party LLMs for inference. Platform code is Go and Helm; the agent harness is TypeScript.
Every diagram in this article was made with A3, and this article was originally published on Substack.
Thanks to my manager Abhijeet Bhanjadeo for backing this work and giving the team room to run with it, and to my teammates Jun Heng Phua and Aaron Lee for starting the idea behind A3.
Footnotes
-
LLMs are provided through an SAP AI Platform governed by NDA and legal contracts with no use of data for re-training. ↩