Code used in this article can be found here
If you’ve been following the rise of AI agents, you’ve probably heard of MCP (Model Context Protocol), and seen the tagline “MCP is like USB for AI.”
USB solved a concrete problem: before it existed, every device needed its own driver and connection protocol. MCP tries to do the same thing for AI tools and context: instead of writing custom integrations for 20 different APIs, you can much more easily integrate 20 MCP servers through a standard protocol.
Many articles only explain MCP conceptually or stop at using the libraries. In this post, we’ll go deeper:
- Start with plain function calling with the OpenAI API, to illustrate the problem
- Move to MCP with official libraries
- Then build minimal clients and servers from scratch with raw JSON-RPC
- Finally, wire MCP tools back into LLMs with function calling
By the end, you’ll see MCP from first principles: not just what it does, but how it works under the hood, and what it’s trying to solve.
Plain Function Calling
Before we get to MCP, it’s worth looking at how you use function calls with today’s LLM APIs - the mechanism that lets models trigger actions or fetch information.
Here’s the baseline: how it looks in practice with OpenAI’s API:
import json
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
openai_client = OpenAI()
# --- Define tools like normal function calling ---
def greet(name: str) -> str:
"""Greet someone by name."""
return f"Hi there {name}! This is an MCP greeting."
def calculate(expression: str) -> str:
"""Evaluate a math expression."""
try:
# Warning: eval() is unsafe in production - use ast.literal_eval or a proper parser
result = eval(expression)
return str(result)
except Exception as e:
return f"Error: {e}"
# Map of available tools
TOOLS = {
"greet": greet,
"calculate": calculate,
}
# Define tool call schema for the model to work with, which we map back to our functions if the model calls tools
openai_tools = [
{
"type": "function",
"name": "greet",
"description": greet.__doc__,
"parameters": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "The name of the person to greet"},
},
"required": ["name"],
},
},
{
"type": "function",
"name": "calculate",
"description": calculate.__doc__,
"parameters": {
"type": "object",
"properties": {
"expression": {"type": "string", "description": "Math expression to evaluate"},
},
"required": ["expression"],
},
},
]
# --- Run one round of query, tool call, tool result, response ---
input_list = [
{"role": "user", "content": "Say hi to John, and also calculate and say the result of (800+256)*287"}
]
# Step 1: Send query to LLM
response = openai_client.responses.create(
model="gpt-4.1",
input=input_list,
tools=openai_tools,
)
# Add model's tool calls back to the input before we add tool results
input_list += response.output
# Step 2: Check if model wants to call a tool
for item in response.output:
if item.type == "function_call":
func_name = item.name
args = json.loads(item.arguments)
print(f"Model is calling tool: {func_name}, with args: {args}")
if func_name in TOOLS:
tool_result = TOOLS[func_name](**args)
print(f"Result of tool {func_name}: {tool_result}")
# Step 3: Add tool output back to input, to send to LLM
input_list.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": tool_result,
})
# Print final input list to show the full flow
print("\nFinal input list:")
for item in input_list:
print(item)
# Step 4: Get final natural-language answer
final = openai_client.responses.create(
model="gpt-4.1",
input=input_list,
tools=openai_tools,
)
print(f"\nFinal model output: {final.output_text}")When you run it, the logs look like this:
Model is calling tool: greet, with args: {'name': 'John'}
Result of tool greet: Hi there John! This is an MCP greeting.
Model is calling tool: calculate, with args: {'expression': '(800+256)*287'}
Result of tool calculate: 303072
Final input list:
{'role': 'user', 'content': 'Say hi to John, and also calculate and say the result of (800+256)*287'}
ResponseFunctionToolCall(arguments='{"name":"John"}', call_id='call_xxxx', name='greet', type='function_call', id='fc_xxxx', status='completed')
ResponseFunctionToolCall(arguments='{"expression":"(800+256)*287"}', call_id='call_xxxx', name='calculate', type='function_call', id='fc_xxxx', status='completed')
{'type': 'function_call_output', 'call_id': 'call_xxxx', 'output': 'Hi there John! This is an MCP greeting.'}
{'type': 'function_call_output', 'call_id': 'call_xxxx', 'output': '303072'}
Final model output: Hi there John! This is an MCP greeting.
Also, the result of (800+256)*287 is 303072.This is the foundation of how most “AI agents” work today. You define tools with a structured schema, pass those schemas to the model, and let the model decide when to use them to call a tool.1
In our example, the model sees a greet tool and a calculate tool. From the prompt - “say hi to John” and “calculate (800+256)*287” - it infers that both should be called. These show up in the response as JSON objects with the tool name and arguments matching the schema we defined.
Because parallel tool calls are enabled by default, the model can make multiple calls in a single step. Our code parses arguments from those calls, executes the functions, and feeds the outputs back. On the next request, the model has access to those results and responds with a final answer.
For multi-step tasks (e.g. search, then calculate, then book a flight), you could just loop until the model stops emitting tool calls.
The problem is that every tool and its schema is hardcoded into your application. Add a new API? More glue code. Want to reuse tools across projects? Copy-paste schemas, or invent your own system.
Take a realistic example: you want your agent to charge a card in Stripe, reply to a customer in Slack, and open an issue in GitHub. Before, you’d wire up three different APIs, each with their own auth, schemas, retries, and quirks.
This is the sort of pain point MCP aims to solve.
MCP basics
MCP tries to solve this, and other repetitive issues with providing context to agents, in a standardised way with a three-layer architecture:
- Host: Your AI app (e.g Claude Desktop, VS Code, custom script), which is possibly using multiple clients to expose context to the models
- Client: Manages a connection to exactly one server, through STDIO (standard input/output) or HTTP
- Server: Exposes tools via a standard protocol
In addition, MCP isn’t just about tools. Servers can also surface resources and prompts, and clients get extra primitives like sampling and elicitation. The idea is to standardize not only tool calls, but the broader set of interactions an agent needs.
How do these components communicate? MCP defines transports, which are the wire formats for carrying JSON-RPC messages (a lightweight remote procedure call protocol) between client and server:
- STDIO Transport: The simplest and default option. The client spawns a server as a subprocess, and they exchange JSON-RPC messages over standard input and output. This is meant for local development or bundling servers with desktop apps.
- HTTP Transport: For servers that live as independent processes or services. Clients send requests to a single /mcp endpoint (with optional Server-Sent Events for streaming). HTTP transport is more natural when running servers in the cloud or exposing them to multiple clients.
Both transports are interchangeable: the JSON-RPC messages are identical, only the medium differs.
Here’s the basic flow between client and server that we’ll implement by the end of this article, which starts with a capability negotiation handshake:
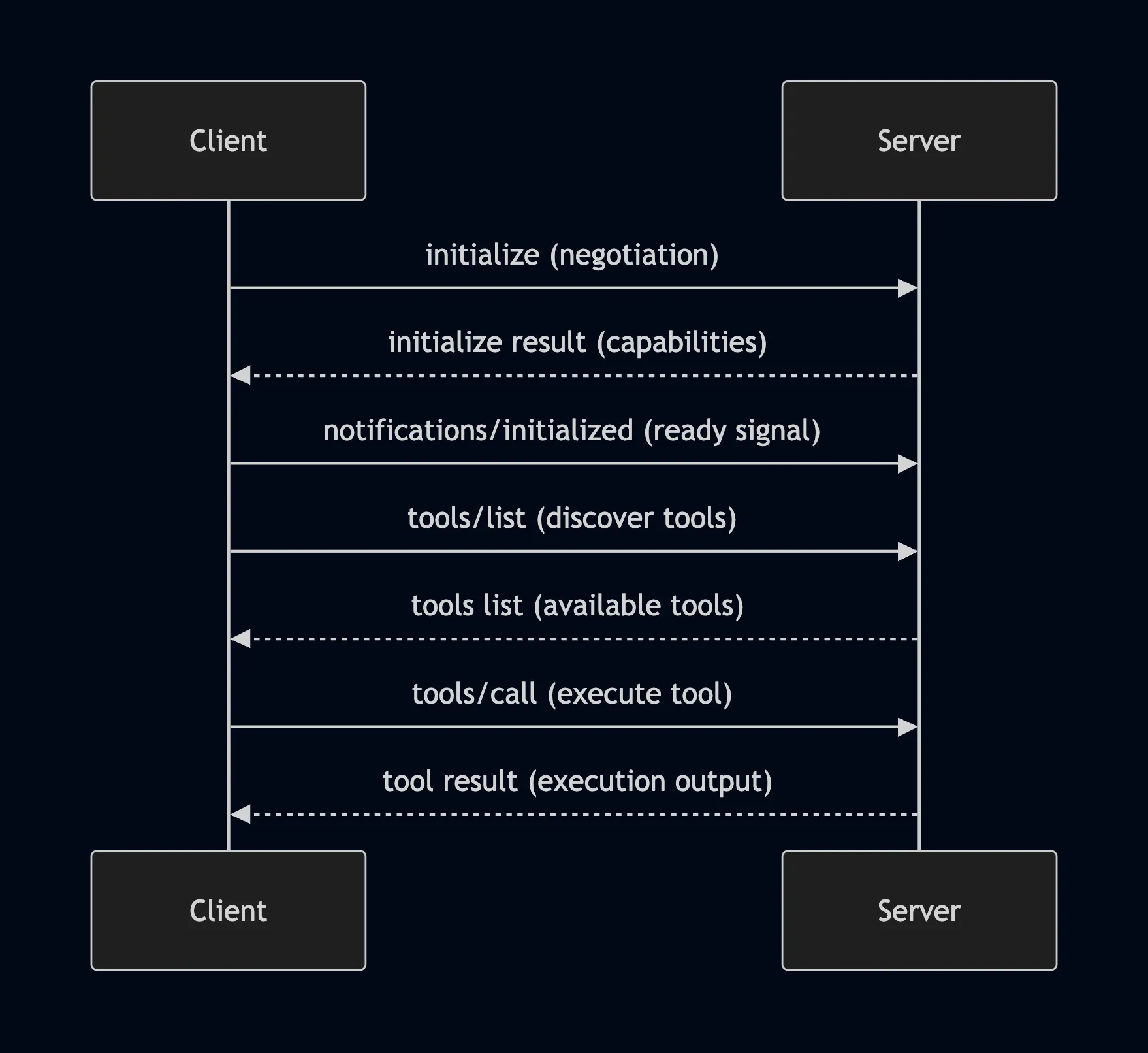
MCP handshake and example execution flow between client and server
How This Looks With Libraries
FastMCP is a popular Python framework for building MCP servers and clients. Here’s a simple server that exposes the same greet and calculate tools we used earlier.
By default, calling mcp.run() starts the server using the STDIO transport, which means all communication happens over process standard input and output.
from fastmcp import FastMCP
mcp = FastMCP("My MCP Server")
@mcp.tool
def greet(name: str) -> str:
"""Greet someone by name."""
return f"Hi there {name}! This is an MCP greeting."
@mcp.tool
def calculate(expression: str) -> int | float:
"""Evaluate a mathematical expression."""
# Warning: eval() is unsafe in production - use ast.literal_eval or a proper parser
return eval(expression)
if __name__ == "__main__":
mcp.run()The client spawns the server and runs a typical flow:
import asyncio
from fastmcp import Client
import logging
import sys
client = Client("fastmcp_server.py")
logging.basicConfig(
stream=sys.stderr,
level=logging.INFO,
format="CLIENT: [%(levelname)s] %(message)s"
)
async def main():
async with client:
# Basic server interaction
res = await client.ping()
logging.info(f"ping {res}")
# List available operations
tools = await client.list_tools()
logging.info(f"Tools: {tools}")
res = await client.call_tool("greet", {"name": "John"})
if res.content:
text: str | None = getattr(res.content[0], "text", None)
if text is not None:
logging.info(f"Tool call result: {text}")
asyncio.run(main())Logs from running the client:
CLIENT: [INFO] ping True
CLIENT: [INFO] Tools: [Tool(name='greet'...)]
CLIENT: [INFO] Tool call result: Hi there John! This is an MCP greeting.What’s happening:
- Client pings the server
- Client lists tools provided by the server
- Client calls the greet tool with an argument - then the server executes it and returns the result
Neat, but what’s actually going on under the hood? FastMCP is handling concerns such as subprocess management, JSON-RPC over stdio, and the protocol lifecycle. Let’s strip away the client library to see the raw messages.
Raw JSON-RPC Client <-> FastMCP server
Here’s a barebones client without the library that does the same interaction with the FastMCP server:
import subprocess
import json
import logging
import sys
# Configure logging: goes to stderr, prefixed with CLIENT:
logging.basicConfig(
stream=sys.stderr,
level=logging.INFO,
format="CLIENT: [%(levelname)s] %(message)s"
)
proc = subprocess.Popen(
["uv", "run", "./fastmcp_server.py"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
text=True
)
def send_msg(msg, label, get_stdout=True):
"""Send a JSON-RPC message and optionally read one line of response."""
if label:
logging.info(label)
json_data = json.dumps(msg)
logging.info(f"Sending -> {json_data}")
if proc.stdin and proc.stdout:
proc.stdin.write(json_data + "\n")
proc.stdin.flush()
if get_stdout:
line = proc.stdout.readline().strip()
logging.info(f"Received <- {line}")
# ---- Step 1: initialize ----
init_msg = {
"jsonrpc": "2.0",
"id": 1,
"method": "initialize",
"params": {
"protocolVersion": "2025-06-18",
"capabilities": {"tools": {}},
"clientInfo": {"name": "raw-client", "version": "0.1"}
}
}
send_msg(init_msg, "Initialize")
# ---- Step 2: send initialized notification ----
initialized_msg = {
"jsonrpc": "2.0",
"method": "notifications/initialized"
}
send_msg(initialized_msg, "Sending notification for initialized", False)
# ---- Step 3: list tools ----
tools_list_msg = {
"jsonrpc": "2.0",
"id": 2,
"method": "tools/list"
}
send_msg(tools_list_msg, "List tools")
# ---- Step 4: call greet ----
call_greet = {
"jsonrpc": "2.0",
"id": 3,
"method": "tools/call",
"params": {
"name": "greet",
"arguments": {"name": "John"}
}
}
send_msg(call_greet, "Call greet response", True)Logs2 show the raw JSON-RPC exchange:
CLIENT: [INFO] Initialize
CLIENT: [INFO] Sending -> {"jsonrpc": "2.0", "id": 1, "method": "initialize", "params": {"protocolVersion": "2025-06-18", "capabilities": {"tools": {}}, "clientInfo": {"name": "raw-client", "version": "0.1"}}}
[09/21/25 16:41:04] INFO Starting MCP server 'My MCP Server' with transport 'stdio' server.py:1495
CLIENT: [INFO] Received <- {"jsonrpc":"2.0","id":1,"result":{"protocolVersion":"2025-06-18","capabilities":{"experimental":{},"prompts":{"listChanged":false},"resources":{"subscribe":false,"listChanged":false},"tools":{"listChanged":true}},"serverInfo":{"name":"My MCP Server","version":"1.14.0"}}}
CLIENT: [INFO] Sending notification for initialized
CLIENT: [INFO] Sending -> {"jsonrpc": "2.0", "method": "notifications/initialized"}
CLIENT: [INFO] List tools
CLIENT: [INFO] Sending -> {"jsonrpc": "2.0", "id": 2, "method": "tools/list"}
CLIENT: [INFO] Received <- {"jsonrpc":"2.0","id":2,"result":{"tools":[{"name":"greet","description":"Greet someone by name.","inputSchema":{"properties":{"name":{"title":"Name","type":"string"}},"required":["name"],"type":"object"},"outputSchema":{"properties":{"result":{"title":"Result","type":"string"}},"required":["result"],"title":"_WrappedResult","type":"object","x-fastmcp-wrap-result":true},"_meta":{"_fastmcp":{"tags":[]}}},{"name":"calculate","description":"Evaluate a mathematical expression.","inputSchema":{"properties":{"expression":{"title":"Expression","type":"string"}},"required":["expression"],"type":"object"},"outputSchema":{"properties":{"result":{"anyOf":[{"type":"integer"},{"type":"number"}],"title":"Result"}},"required":["result"],"title":"_WrappedResult","type":"object","x-fastmcp-wrap-result":true},"_meta":{"_fastmcp":{"tags":[]}}}]}}
CLIENT: [INFO] Call greet response
CLIENT: [INFO] Sending -> {"jsonrpc": "2.0", "id": 3, "method": "tools/call", "params": {"name": "greet", "arguments": {"name": "John"}}}
CLIENT: [INFO] Received <- {"jsonrpc":"2.0","id":3,"result":{"content":[{"type":"text","text":"Hi there John! This is an MCP greeting."}],"structuredContent":{"result":"Hi there John! This is an MCP greeting."},"isError":false}}In this script, we try to implement what the FastMCP client was doing. We spawn the FastMCP server as a process, and communicate with it over raw standard input and output following the JSON-RPC format specified in the protocol. Messages are delimited by newlines for the stdio transport.
What’s happening:
- initialize → handshake and version negotiation.
- notifications/initialized → client signals readiness.3
- tools/list → server responds with available tool schemas.
- tools/call → server executes greet(“John”) and returns the result.
Zooming In
Let’s zoom in a bit on some of the messages involved in the flow above.
Initialize
The initialize process is where protocol version and capability negotiation happen: client and server declare what features they support (e.g. tools, resources, prompts), and both sides must respect these capabilities throughout the session.
One part of this is "tools": {"listChanged": true}, which signals that the tool set can change dynamically. In that case, the server will emit tools/list_changed notifications, and the client must refresh the tool list. listChanged can also apply to prompts and resources.
// sent from server
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"protocolVersion": "2025-06-18",
"capabilities": {
... // other capabilities like resources and prompts
"tools": {
"listChanged": true
}
},
"serverInfo": {
"name": "My MCP Server",
"version": "1.14.0"
}
}
}Initialized Notification
After a successful initialize response, the client must send an initialized notification to signal readiness. Until then, technically only pings and logs should be exchanged - no other requests are valid.
// sent from client
{
"jsonrpc": "2.0",
"method": "notifications/initialized"
}As you can see in the logs above, the client sends this notification immediately after the initialize handshake, before proceeding to list tools.
Tool Schemas
Notice that each tool in thetools/list response includes an inputSchema (arguments the tool expects) and an outputSchema (what the result should look like). The outputSchema is optional, but if provided the client is expected to validate results against it.
// sent from server
{
"tools": [
{
"name": "greet",
"description": "Greet someone by name.",
"inputSchema": {
"type": "object",
"properties": {
"name": { "title": "Name", "type": "string" }
},
"required": ["name"]
},
"outputSchema": {
"type": "object",
"title": "_WrappedResult",
"properties": {
"result": { "title": "Result", "type": "string" }
},
"required": ["result"],
"x-fastmcp-wrap-result": true
}
},
{
"name": "calculate",
...
}
]
}Structured Content
Additionally, when a tool defines an outputSchema, the server includes the result in the structuredContent field during tools/call. For compatibility with older clients, the same data is also serialized into the unstructured content array. This is why the result has both content and structuredContent fields with the same information.
// sent from server
{
"jsonrpc": "2.0",
"id": 3,
"result": {
"content": [
{
"type": "text",
"text": "Hi there John! This is an MCP greeting."
}
],
"structuredContent": {
"result": "Hi there John! This is an MCP greeting."
},
"isError": false
}
}Shutdown
The last phase is shutdown. MCP doesn’t define a special message - you just close the underlying transport:
- stdio: client closes the input stream to the server and waits for it to exit (falling back to
SIGTERM/SIGKILLif needed). The server can also initiate shutdown. - HTTP: shutdown just means closing the HTTP connection(s).
This summarises what FastMCP is doing under the hood: MCP in a simplified sense is just exchanging messages in JSON-RPC 2.0 over a transport (stdio or HTTP) while tracking any state necessary to implement the protocol.
Raw JSON-RPC Server <-> FastMCP client
Now, let’s flip it and write a minimal MCP server that the FastMCP client can talk to, which supports just a greet tool:
import sys
import json
import logging
# Configure logging to stderr (never stdout!)
logging.basicConfig(
stream=sys.stderr,
level=logging.INFO,
format="SERVER: [%(levelname)s] %(message)s"
)
def send(msg):
"""Send a JSON-RPC message to stdout."""
sys.stdout.write(json.dumps(msg) + "\n")
sys.stdout.flush()
def recv():
"""Read one line from stdin and parse as JSON."""
line = sys.stdin.readline()
if not line:
return None
return json.loads(line)
def handle_request(req):
logging.info(f"Received request: {req}")
if req["method"] == "initialize":
return {
"jsonrpc": "2.0",
"id": req["id"],
"result": {
"protocolVersion": "2025-06-18",
"capabilities": {"tools": {"listChanged": True}},
"serverInfo": {"name": "SimpleServer", "version": "0.1"},
},
}
elif req["method"] == "tools/list":
return {
"jsonrpc": "2.0",
"id": req["id"],
"result": {
"tools": [
{
"name": "greet",
"description": "Greet someone by name.",
"inputSchema": {
"type": "object",
"properties": {"name": {"type": "string"}},
"required": ["name"],
},
# no outputSchema for simplicity
}
]
},
}
elif req["method"] == "tools/call":
args = req["params"]["arguments"]
name = args.get("name", "stranger")
return {
"jsonrpc": "2.0",
"id": req["id"],
"result": {
"content": [{"type": "text", "text": f"Hello, {name}!"}],
"isError": False, # in actual implementation, we'd use this to indicate tool errors
},
}
elif req["method"] == 'notifications/initialized':
return None # No response needed for notifications
else:
logging.warning(f"Unknown method: {req['method']}")
return {
"jsonrpc": "2.0",
"id": req["id"],
"error": {"code": -32601, "message": "Method not found"},
}
if __name__ == "__main__":
logging.info("Simple MCP server starting up...")
while True:
req = recv()
if req is None:
break
resp = handle_request(req)
if resp:
send(resp)Run it with the FastMCP client and the logs are similar to what we saw earlier, but from both server and client.
SERVER: [INFO] Simple MCP server starting up...
SERVER: [INFO] Received request: {'method': 'initialize', 'params': {'protocolVersion': '2025-06-18', 'capabilities': {}, 'clientInfo': {'name': 'mcp', 'version': '0.1.0'}}, 'jsonrpc': '2.0', 'id': 0}
SERVER: [INFO] Received request: {'method': 'notifications/initialized', 'jsonrpc': '2.0'}
SERVER: [INFO] Received request: {'method': 'ping', 'jsonrpc': '2.0', 'id': 1}
CLIENT: [INFO] ping True
SERVER: [INFO] Received request: {'method': 'tools/list', 'jsonrpc': '2.0', 'id': 2}
CLIENT: [INFO] Tools: [Tool(name='greet', title=None, description='Greet someone by name.', inputSchema={'type': 'object', 'properties': {'name': {'type': 'string'}}, 'required': ['name']}, outputSchema={'type': 'object', 'properties': {'result': {'type': 'string'}}, 'required': ['result']}, annotations=None, meta=None)]
SERVER: [INFO] Received request: {'method': 'tools/call', 'params': {'name': 'greet', 'arguments': {'name': 'John'}, '_meta': {'progressToken': 3}}, 'jsonrpc': '2.0', 'id': 3}
CLIENT: [INFO] Tool call result: Hello, John!We essentially run a loop that reads JSON-RPC requests from stdin and writes responses back to stdout. The server handles the minimal methods for this exchange: initialize (handshake and capability negotiation), tools/list (advertise available tools), tools/call (execute a tool and return the result), and notifications/initialized (acknowledge client readiness).
Errors also follow the JSON-RPC 2.0 standard. For example, -32601 is the official “Method not found” error code, which we return when the client calls an unsupported method.
This is only a slice of the full MCP spec (no resources, prompts, notifications, etc), but it’s hopefully enough to demonstrate that MCP isn’t magic.
Since it’s just a protocol, we can even have the raw server and client communicate with each other without FastMCP. Change this line in the raw client to spawn the appropriate process:
proc = subprocess.Popen(["uv", "run", "./simple_server.py"], ...)Wiring MCP Back Into LLMs
Finally, we can tie it all back to function calling to see how MCP integrates with LLMs. The script below shows how we would integrate tools from a MCP server with an LLM for it to be able to take actions:
import asyncio, json
from openai import OpenAI
from fastmcp import Client
from dotenv import load_dotenv
load_dotenv()
openai_client = OpenAI()
mcp_client = Client("fastmcp_server.py") # path to executable for MCP server process
async def main():
async with mcp_client:
# fetch tool list from MCP
mcp_tools = await mcp_client.list_tools()
print("MCP tools:", mcp_tools, "\n")
openai_tools = mcp_tools_to_openai(mcp_tools)
print("OpenAI formatted tools:", openai_tools, "\n")
# step 1: send user query + tools to LLM
input_list = [{"role": "user", "content": "Say hi to John, and also calculate and say the result of (800+256)*287"}]
response = openai_client.responses.create(
model="gpt-4.1",
input=input_list,
tools=openai_tools
)
input_list += response.output
# step 2: check if model wants to call a tool
for item in response.output:
if item.type == "function_call":
args = json.loads(item.arguments)
print(f"Model is calling MCP tool: {item.name}, with args: {args}")
# forward to MCP
mcp_result = await mcp_client.call_tool(item.name, args)
print("MCP tool result:", mcp_result)
# extract result: try structured_content, then .data, fallback to str of whole object
result_str = (
mcp_result.structured_content.get("result")
if hasattr(mcp_result, "structured_content") and mcp_result.structured_content
else str(mcp_result.data) if hasattr(mcp_result, "data") else str(mcp_result)
)
# step 3: send tool output back to LLM
input_list.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": json.dumps({"result": result_str}),
})
print("\nFinal input list:")
for item in input_list:
print(item)
# # step 4: get final natural-language answer
final = openai_client.responses.create(
model="gpt-4.1",
input=input_list,
tools=openai_tools,
)
print("\nFinal model output:",final.output_text)
def mcp_tools_to_openai(tools):
return [
{
"type": "function",
"name": t.name,
"description": t.description or "",
"parameters": t.inputSchema,
}
for t in tools
]
asyncio.run(main())Example logs from a run:
MCP tools: [Tool(name='greet', title=None, description='Greet someone by name.', inputSchema={'properties': {'name': {'title': 'Name', 'type': 'string'}}, 'required': ['name'], 'type': 'object'}, outputSchema={'properties': {'result': {'title': 'Result', 'type': 'string'}}, 'required': ['result'], 'title': '_WrappedResult', 'type': 'object', 'x-fastmcp-wrap-result': True}, annotations=None, meta={'_fastmcp': {'tags': []}}), Tool(name='calculate', title=None, description='Evaluate a mathematical expression.', inputSchema={'properties': {'expression': {'title': 'Expression', 'type': 'string'}}, 'required': ['expression'], 'type': 'object'}, outputSchema={'properties': {'result': {'anyOf': [{'type': 'integer'}, {'type': 'number'}], 'title': 'Result'}}, 'required': ['result'], 'title': '_WrappedResult', 'type': 'object', 'x-fastmcp-wrap-result': True}, annotations=None, meta={'_fastmcp': {'tags': []}})]
OpenAI formatted tools: [{'type': 'function', 'name': 'greet', 'description': 'Greet someone by name.', 'parameters': {'properties': {'name': {'title': 'Name', 'type': 'string'}}, 'required': ['name'], 'type': 'object'}}, {'type': 'function', 'name': 'calculate', 'description': 'Evaluate a mathematical expression.', 'parameters': {'properties': {'expression': {'title': 'Expression', 'type': 'string'}}, 'required': ['expression'], 'type': 'object'}}]
Model is calling MCP tool: greet, with args: {'name': 'John'}
MCP tool result: CallToolResult(content=[TextContent(type='text', text='Hi there John! This is an MCP greeting.', annotations=None, meta=None)], structured_content={'result': 'Hi there John! This is an MCP greeting.'}, data='Hi there John! This is an MCP greeting.', is_error=False)
Model is calling MCP tool: calculate, with args: {'expression': '(800+256)*287'}
MCP tool result: CallToolResult(content=[TextContent(type='text', text='303072', annotations=None, meta=None)], structured_content={'result': 303072}, data=303072, is_error=False)
Final input list:
{'role': 'user', 'content': 'Say hi to John, and also calculate and say the result of (800+256)*287'}
ResponseFunctionToolCall(arguments='{"name":"John"}', call_id='call_xxxx', name='greet', type='function_call', id='fc_xxxx', status='completed')
ResponseFunctionToolCall(arguments='{"expression":"(800+256)*287"}', call_id='call_xxxx', name='calculate', type='function_call', id='fc_xxxx', status='completed')
{'type': 'function_call_output', 'call_id': 'call_xxxx', 'output': '{"result": "Hi there John! This is an MCP greeting."}'}
{'type': 'function_call_output', 'call_id': 'call_xxxx', 'output': '{"result": 303072}'}
Final model output: Hi there John! This is an MCP greeting.
Also, the result of (800+256)*287 is 303,072.What this script does:
- Spawns an MCP server and dynamically pulls its tool list (
list_tools). - Converts MCP’s tool schemas into the function-calling format expected by OpenAI
- Sends the user query + tool list to the LLM.
- When the model emits tool calls, forwards them to the MCP server (
tools/call). - Collects the results, feeds them back to the LLM, and gets a final natural-language answer.
The flow looks similar to plain function calling, but now the MCP server is instead the source of truth and execution.
- Before: tools and schemas, including tool execution were hardcoded in your app.
- Now: the client discovers them with
list_toolsand invokes them withtools/call.
This makes it relatively easy for an application to connect models to multiple MCP servers, each exposing its own tools, resources, or prompts, with much less custom glue code.
Back to the earlier Stripe/Slack/GitHub example - instead of you writing three separate integrations, you can just point your client at:
Each one speaks the same protocol. Your app doesn’t care whether the tool is for payments, chat, or code - discovery and execution look identical.
Bonus: HTTP MCP Server with FastAPI
So far, we’ve used the stdio transport. But MCP also supports Streamable HTTP, where the server runs as an independent process and clients talk to it over HTTP.
Here’s a minimal FastAPI MCP server that exposes a greet tool:
# FastAPI server implementing a basic MCP server without FastMCP
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse, Response
import uvicorn
import logging
app = FastAPI()
logging.basicConfig(level=logging.INFO, format="SERVER: [%(levelname)s] %(message)s")
PROTOCOL_VERSION = "2025-06-18"
@app.post("/mcp")
async def mcp_endpoint(req: Request):
body = await req.json()
logging.info(f"Received request: {body}")
method = body.get("method")
req_id = body.get("id")
if method == "initialize":
return JSONResponse({
"jsonrpc": "2.0",
"id": req_id,
"result": {
"protocolVersion": PROTOCOL_VERSION,
"capabilities": {"tools": {"listChanged": False}},
"serverInfo": {"name": "SimpleHTTPServer", "version": "0.1"},
}
})
elif method == "ping":
return JSONResponse({
"jsonrpc": "2.0",
"id": req_id,
"result": {},
})
elif method == "tools/list":
return JSONResponse({
"jsonrpc": "2.0",
"id": req_id,
"result": {
"tools": [
{
"name": "greet",
"description": "Greet someone by name.",
"inputSchema": {
"type": "object",
"properties": {"name": {"type": "string"}},
"required": ["name"],
},
}
]
}
})
# just the greet tool for simplicity
elif method == "tools/call":
args = body["params"]["arguments"]
name = args.get("name", "stranger")
text_result = f"Hello, {name}!"
return JSONResponse({
"jsonrpc": "2.0",
"id": req_id,
"result": {
# Free-form content
"content": [
{"type": "text", "text": text_result}
],
"isError": False,
}
})
elif method == "notifications/initialized":
# Notifications don’t expect a response
return Response(status_code=204)
else:
logging.warning(f"Unknown method: {method}")
return JSONResponse({
"jsonrpc": "2.0",
"id": req_id,
"error": {"code": -32601, "message": "Method not found"},
})
if __name__ == "__main__":
logging.info("Starting HTTP MCP server...")
uvicorn.run(app, host="127.0.0.1", port=8000)Start the server, then point the FastMCP client at the endpoint:
client = Client("http://127.0.0.1:8000/mcp")What’s different here?
- Instead of stdin/stdout, every JSON-RPC message is HTTP POST to a route like /mcp.
- The spec also states that servers should implement HTTP GET with SSE for server-to-client pushes, which we skip here for simplicity.
- Servers should implement proper authentication for all connections.
Otherwise, it’s mostly the same protocol, just a different transport.
The code we wrote covers the core MCP patterns, but the full spec is much more comprehensive, which is why using one of the available libraries is likely a better idea for actual product use than rolling your own implementation. See the complete specification for more details.
Why This Matters
We’ve gone from hardcoded functions to dynamic tool discovery and execution using nothing but JSON-RPC over stdin/stdout and HTTP.
The benefit is practical: adding a new tool doesn’t require rewriting your application logic, and third-party servers can plug in immediately.
MCP helps providers too. It gives a standard way to expose tools, resources, and prompts, so you don’t have to rebuild schemas for every integration. Servers can change or add capabilities without clients rewriting glue code, and models see those capabilities in a consistent format across different clients.
Flaws & Risks
MCP is powerful, but it’s not without limitations:
- Security risks: MCP enables powerful integrations but also centralizes access, which increases the impact of familiar issues like token theft, malicious or compromised servers, injection attacks, and data aggregation. Mitigations include scoped permissions, signed builds, sandboxing, user confirmation, and strong logging. (Red Hat, Pillar Security)
- Tool Design Matters: MCP assumes clients can automatically discover and use tools from servers. In practice, not all tools are designed well: unclear names, vague or conflicting descriptions, and poorly structured parameters can confuse models. Since LLM behavior is highly sensitive to how tools are presented, badly written tools can lead to worse agent performance.
- Often, just wrapping an existing API with a tool isn’t enough: to get good agent performance, you may have to redesign the inputs, outputs, error information, and so on. (Anthropic: Writing effective tools for agents)
- Context & Scale Overhead: Each tool/resource description consumes tokens. With large toolsets, this eats into the model’s context window and can degrade performance. (MCPToolBench++)
These aren’t deal-breakers, but they’re worth keeping in mind when building real systems with MCP.
Footnotes
-
Of course, there’s more to agents than just tool calling - planning, memory, and reasoning all matter. This post from Anthropic gives a good overview. ↩
-
We log to stderr because stdout is reserved for the JSON-RPC protocol. If logs accidentally go to stdout, they’ll corrupt the message stream and break client–server communication. ↩
-
The client doesn’t read the server’s response for this message since the server doesn’t have to respond to this notification. ↩